Alibaba Cloud CTO Zhou Jingren announced the open-source initiatives at a press conference. Photo credit: Alibaba Cloud
Alibaba Cloud said on Monday that it has made two large language models and a model that understands audio freely available as it looks to build the most open cloud in the AI era.
The cloud computing company is opening access to the 72-billion-parameter and 1.8-billion-parameter versions of its proprietary foundation model Tongyi Qianwen.
It’s also making more multimodal LLMs freely available including Qwen-Audio and Qwen-Audio-Chat, a pre-trained audio understanding model and its conversationally finetuned version for research and commercial purposes.
The initiative helps businesses of all sizes to leverage LLMs to create tailored solutions. As of now, Alibaba Cloud has contributed LLMs with parameters ranging from 1.8 billion, 7 billion, 14 billion to 72 billion, as well as multimodal LLMs with audio and visual understanding.
“Building up an open-source ecosystem is critical to promoting the development of LLM and AI applications building. We aspire to become the most open cloud and make generative AI capabilities accessible to everyone,” said Alibaba Cloud’s CTO Zhou Jingren.
Family of LLMs
Scaling pre-trained large language models typically leads to higher performance, but training and running larger models requires greater computational resources.
In light of this, Alibaba Cloud has open-sourced its 1.8-billion-parameter LLM, Qwen-1.8B, which is optimized for smaller devices and offers a more cost-effective option for research purposes. Requiring less computing power, it can run on cell phones that have significantly fewer computational resources and memory than cloud servers. It also means that the LLM-powered applications can still function with limited or no network connection.
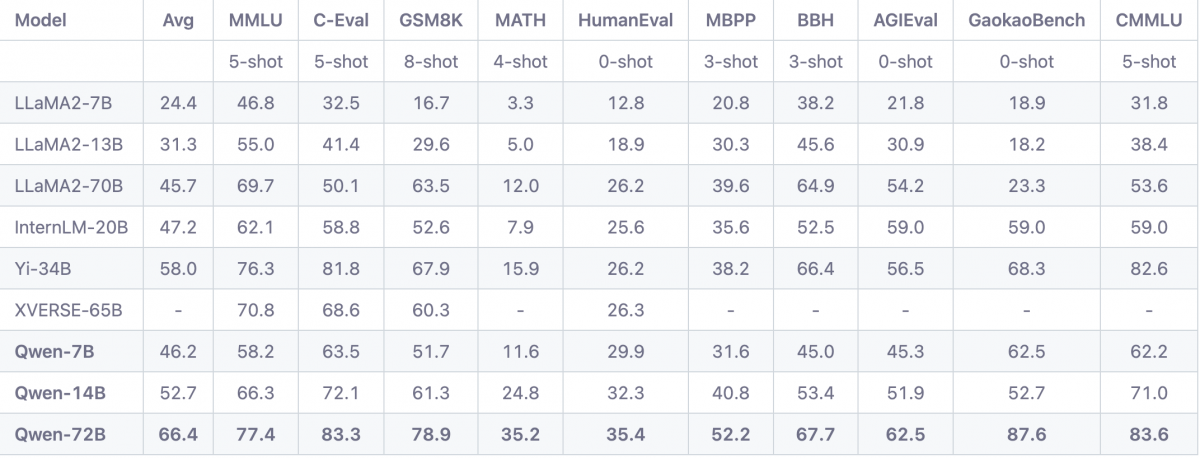
Meanwhile, Alibaba Cloud said its 72-billion-parameter, Qwen-72B, has outperformed other major open-source models against ten benchmarks, including the Massive Multi-task Language Understanding benchmark that measures the model’s multitask accuracy, HumanEval that tests code-generation capabilities and GSM8K, a standard for solving math problems.
The model also outperformed when role-playing and in language-style transfer, which are core to the building of personalized chatbots.
Multimodal Push
Alibaba Cloud is also making strides in integrating multimodality into its LLMs, that is the ability to process data other than text into LLMs.
It has open-sourced the Qwen-Audio and Qwen-Audio-Chat models for research and commercial purposes.
Qwen-Audio can understand text and audio, including human speech, natural sounds and music. It can perform over 30 audio-processing tasks, such as multi-language transcription, speech editing and audio-caption analysis. Its conversationally finetuned version can detect emotions and tones in human speech.
The multimodal push builds on Alibaba Cloud’s previous initiatives of open-sourcing its Large Vision Language Model Qwen-VL and its chat version Qwen-VL-Chat that can understand visual information and perform visual tasks.
The open-sourced LLM models, including Qwen-7B, Qwen-14B and Qwen-VL and their conversationally finetuned versions, have been downloaded over 1.5 million times in total on Alibaba Cloud’s open-source AI model community ModelScope and Hugging Face since August, according to the latest data from Alibaba Cloud.