-小图.jpg)
Alibaba Cloud has unveiled its latest visual-language model, Qwen2.5-VL, which significantly enhances its predecessor, Qwen2-VL. This open-source, multimodal model is offered in various sizes, ranging from 3 billion, 7 billion to 72 billion parameters, and includes both base and instruction-tuned versions. The flagship model, Qwen2.5-VL-72B-Instruct, is now accessible through the Qwen Chat platform, while the entire Qwen2.5-VL series is available on Hugging Face and Alibaba’s open-source community Model Scope.
Qwen2.5-VL demonstrates remarkable multimodal capabilities, excelling in advanced visual comprehension of texts, charts, diagrams, graphics, and layouts within images. It can also understand videos longer than an hour and answer video-related questions, while accurately identifying specific segments down to the exact second. Additionally, the model can generate structured outputs, such as in JSON format, turning unstructured data from scans of invoices, forms, or tables into organized information, which is particularly useful for automating the processing of financial reports or legal documents.
By combining parsing and localization capabilities, Qwen2.5-VL can also serve as a visual agent to facilitate the execution of simple tasks on computers and mobile devices, such as checking the weather and booking a flight ticket, through directing the use of various tools.
Notably, the flagship model Qwen2.5-VL-72B-Instruct achieves competitive performance in a series of benchmarks covering domains and tasks including document and diagrams reading, general visual question answering, college-level math, video understanding, and visual agent.
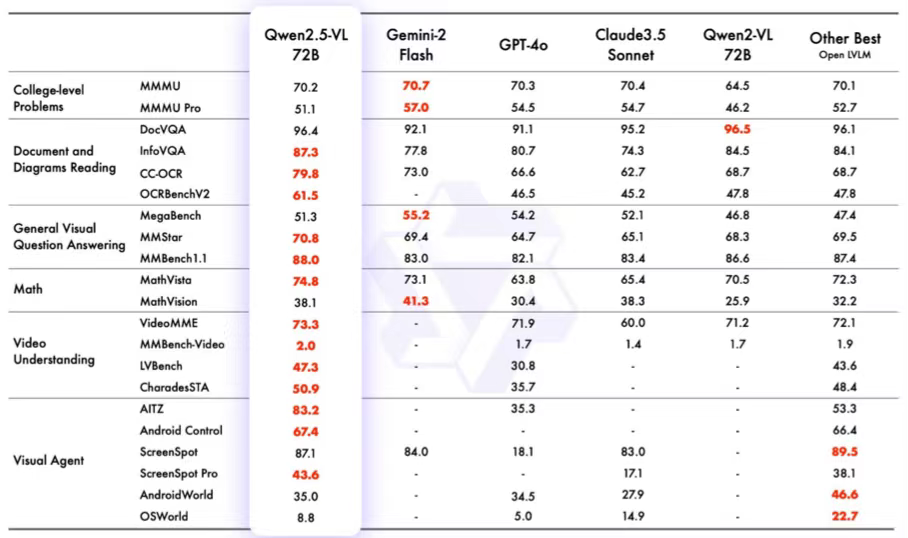
To improve the multimodal performance, researchers behind the model has implemented dynamic resolution and frame rate training to improve video understanding. They have also introduced a more streamlined and efficient visual encoder. This has significantly improved both training and inference speeds by utilizing Window Attention mechanisms within a dynamic Vision Transformer (ViT) architecture. These innovations make Qwen2.5-VL a versatile and powerful tool for complex multimodal applications across sectors.
Expanding Context Input to 1 Million Tokens
In addition, Alibaba Cloud unveiled its latest version of the Qwen large language model, known as Qwen2.5-1M. This open-source iteration is distinguished by its capability to process long context inputs, with the ability to handle up to 1 million tokens.
Generally, the capacity to manage longer contexts allows models to address more complex real-world scenarios that demand substantial information processing or generation. As a result, expanding the context window of large language models (LLMs) can better handle tasks such as long-form document digestion and generation, making long-context LLMs emerged as a new trend.
The release this time includes two versions of instruction-tuned models, Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, which feature 7 billion and 14 billion parameters, respectively. Both versions were made available on Hugging Face, and their technical report has also been published.
In addition, the cloud and AI pioneer has released a corresponding inference framework optimized for processing long contexts on Github. This framework is tailored to help developers deploy the Qwen2.5-1M series more cost-effectively. By leveraging techniques such as length extrapolation and sparse attention, the framework can process 1-million-token inputs with speeds 3 to 7 times faster than traditional approaches, offering a potent solution for developing applications that require long-context processing with more efficiency.
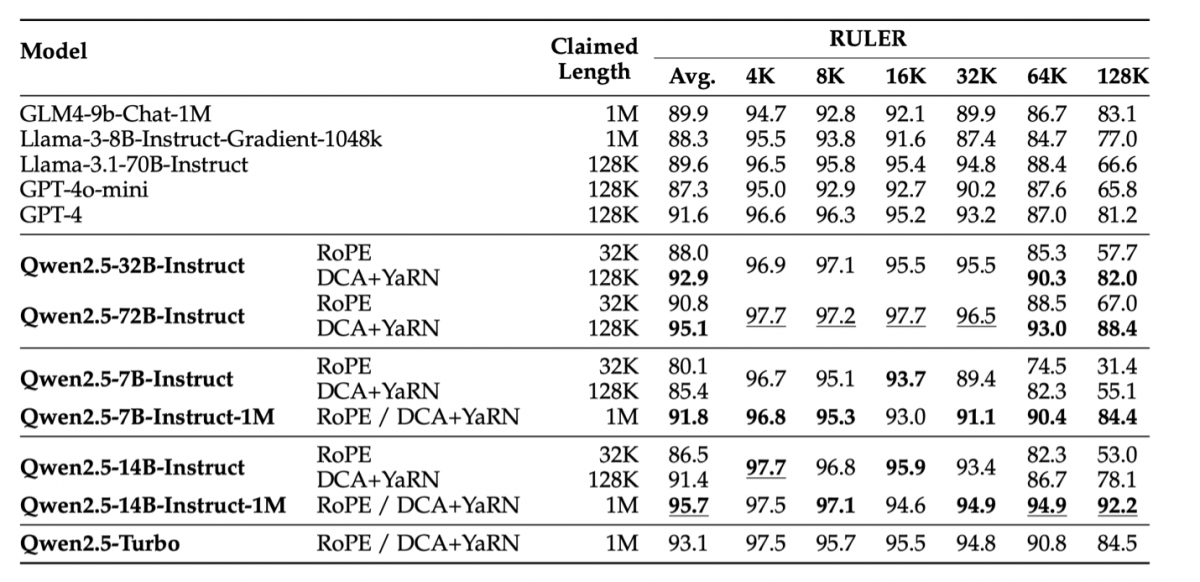
The Qwen2.5-1M series has demonstrated impressive performance in benchmarks focused on long-context capabilities, such as RULER, LV-Eval, and Longbench-Chat. These remarkable results indicate that Qwen2.5-1M provides a robust open-source alternative for tasks demanding extensive context inputs.
Compared to its predecessor, the 128K version, the Qwen2.5-1M series boasts significantly enhanced long-context capabilities, achieved through advanced strategies in long-context pre-training and post-training. Techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to boost long-context performance while effectively reducing training costs.