
generated by chat.qwen.ai
This article has been updated to include the top AI model list and downloads on open-source community Hugging Face on April 5.
Qwen25-Omni-7B, a unified end-to-end multimodal model in the Qwen series released by Alibaba Cloud last week, topped the AI model list on the open-source community Hugging Face, with over 80,000 downloads in around one week since its debut.

Uniquely designed for comprehensive multimodal perception, Qwen2.5-Omni-7B can process diverse inputs, including text, images, audio, and videos, while generating real-time text and natural speech responses. This sets a new standard for optimal deployable multimodal AI for edge devices like mobile phones and laptops.
Despite its compact 7B-parameter design, Qwen2.5-Omni-7B delivers uncompromised performance and powerful multimodal capabilities. This unique combination makes it the perfect foundation for developing agile, cost-effective AI agents that deliver tangible value, especially intelligent voice applications. For example, the model could be leveraged to transform lives by helping visually impaired users navigate environments through real-time audio descriptions, offering step-by-step cooking guidance by analyzing video ingredients, or powering intelligent customer service dialogues that really understand customer needs.
The model is now open-sourced on Hugging Face and GitHub, with additional access via Qwen Chat and Alibaba Cloud’s open-source community ModelScope. Over the past years, Alibaba Cloud has made over 200 generative AI models open-source.
High Performance Driven by Innovative Architecture
Qwen2.5-Omni-7B delivers remarkable performance across all modalities, rivaling specialized single-modality models of comparable size. Notably, it sets a new benchmark in real-time voice interaction, natural and robust speech generation, and end-to-end speech instruction following.
Its efficiency and high performance stem from its innovative architecture, including Thinker-Talker Architecture, which separates text generation (through Thinker) and speech synthesis (through Talker) to minimize interference among different modalities for high-quality output; TMRoPE (Time-aligned Multimodal RoPE), a position embedding technique to better synchronize the video inputs with audio for coherent content generation; and Block-wise Streaming Processing, which enables low-latency audio responses for seamless voice interactions.
Outstanding Performance Despite Compact Size
Qwen2.5-Omni-7B was pre-trained on a vast, diverse dataset, including image-text, video-text, video-audio, audio-text, and text data, ensuring robust performance across tasks.
With the innovative architecture and high-quality pre-trained dataset, the model excels in following voice command, achieving performance levels comparable to pure text input. For tasks that involve integrating multiple modalities, such as those evaluated in OmniBench – a benchmark that assesses models’ ability to recognize, interpret, and reason across visual, acoustic, and textual inputs – Qwen2.5-Omni achieves state-of-the-art performance.
Qwen2.5-Omni-7B also demonstrates high performance on robust speech understanding and generation capabilities through in-context learning (ICL). Additionally, after reinforcement learning (RL) optimization, Qwen2.5-Omni-7B showed significant improvements in generation stability, with marked reductions in attention misalignment, pronunciation errors, and inappropriate pauses during speech response.
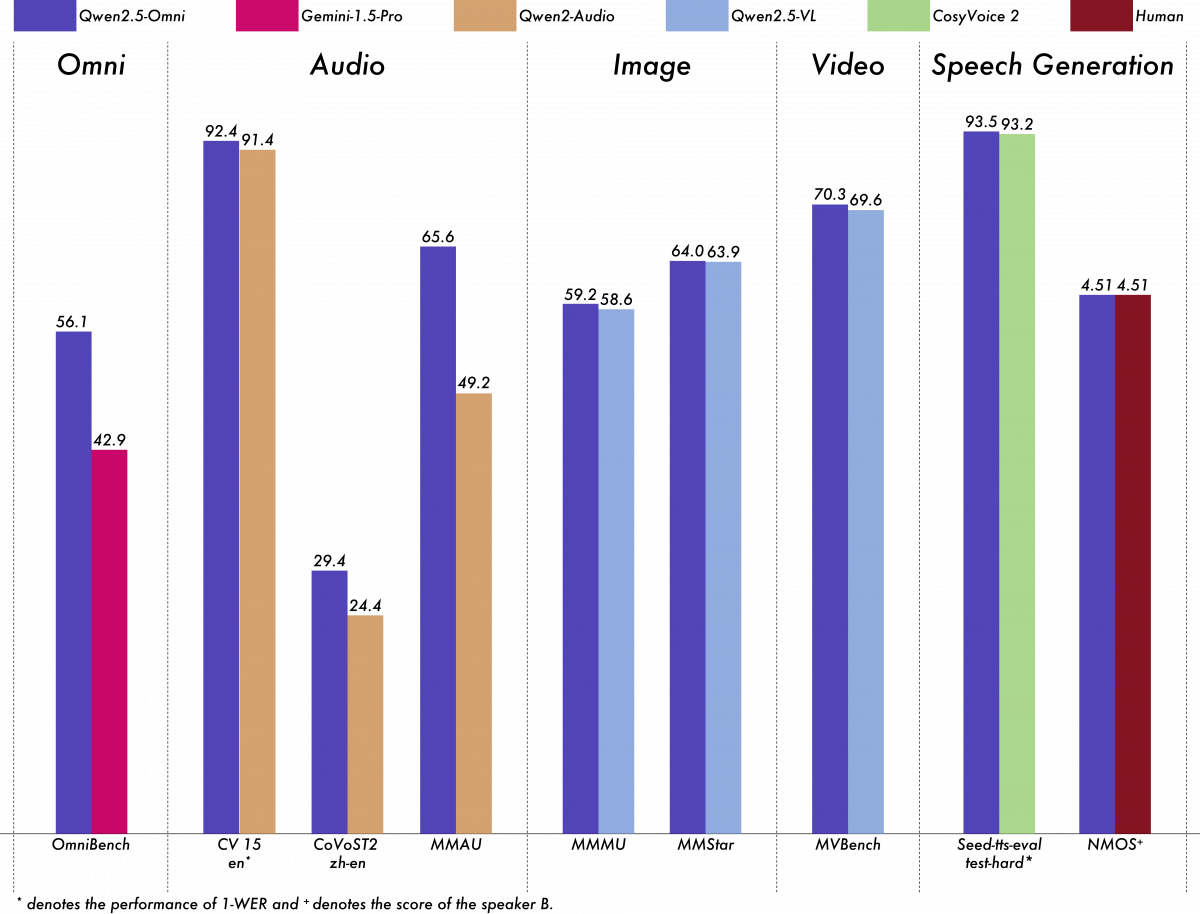
Alibaba Cloud unveils Qwen2.5 last September and released Qwen2.5-Max in January, which was ranked 7th on Chatbot Arena, matching other top proprietary LLMs and demonstrates exceptional capabilities. Alibaba Cloud also open-sourced Qwen2.5-VL and Qwen2.5-1M for enhanced visual understanding and long context input handling.




